Stable Video Diffusion — Convert Text and Images to Videos
Stability AI, one of the leading players in the image generation space, has come up with a brand new model for video generation: Stable Video Diffusion (SVD). It's their first foundation model for generating videos. It's capable of generating videos at 14 and 25 frames at customizable frame rates between 3 and 30 frames per second. The performance surpasses the leading closed models from runway and pika labs.
In this post let's dive into their research paper, and find out more about the three-stage training process proposed specifically for video generation. the model architecture, the training pipeline, and some of the practical applications of the model at scale using the base model released with the paper.
Visual Explanation
If you are a visual learner like me, you might prefer watching the SVD model explained through a video here:
Model Architecture
The model architecture is a modification to the Latent Diffusion Model(LDM). The UNet used for denoising in an LDM consists of spatial 2D convolutions that process the height, width, and channels of the input images. But videos have another dimension which is time.
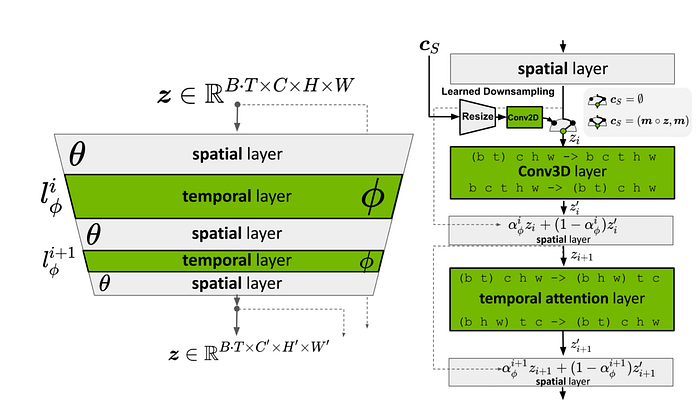
The paper titled, “High-resolution video synthesis with latent diffusion models” introduces temporal layers to process videos for video generation. It introduces 3D convolution and temporal attention layers (shown in green in this figure above) along with the existing spatial layers of the latent diffusion model. SVD adapts this model architecture without modifications. The biggest contribution of SVD is the training stages and the LVD dataset which we will dive into next.
Training Stages
With that architecture in place, they train the model in 3 stages namely, Image pretraining, Curating a Video Pretraining Dataset, and High-Quality Finetuning
Image pretraining
For the first stage of image pretraining, they used stable diffusion 2.1 which is their best image model for data. This model is equipped with strong visual representations which serve as a very good starting point
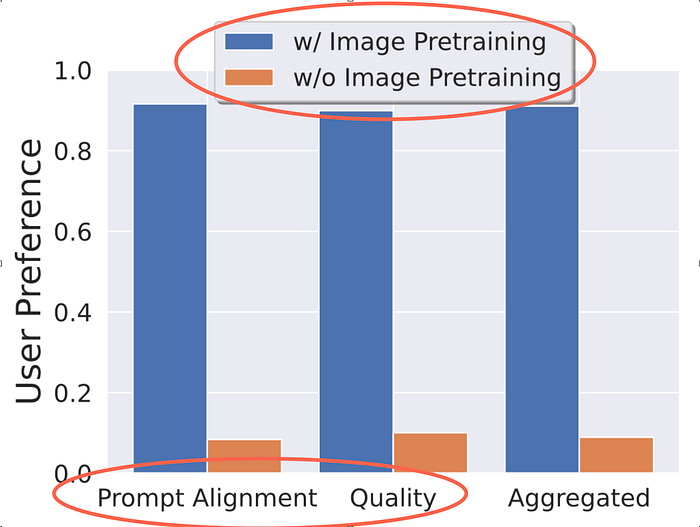
To emphasize the importance of image pre-training, they compare two models trained on the same dataset — one with pretraining and one without pretraining. They studied which of the two models the user preferred both in terms of prompt alignment and generated image quality. The results favour image pre-training indicating its significance.
Curating a Video Pretraining Dataset
The next stage is the video curation stage to collate a video pretraining dataset. They motivate this data curation step by saying that “leveraging efficient language-image representations such as CLIP data curation has similarly been successfully applied for generative image modeling. However, discussions on such data curation strategies have largely been missing in the video generation literature. The only publicly available video dataset is the WebVid-10 million. Even this dataset seems to be a mix of both images and videos. So Stability AI decided to build and curate their video dataset.
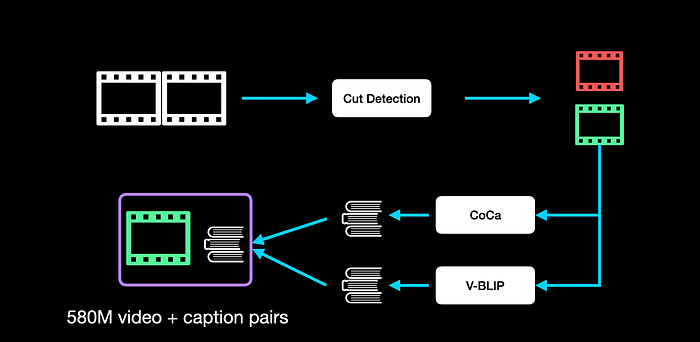
So for the video data curation, they develop a pipeline where they start with an initial dataset of long videos. These videos are then passed through a cut detection pipeline to divide the videos into clips based on where cuts happen. The resulting cuts are passed through the CoCa image captioning model to caption the central frame in the clip. The clips are also passed through V-BLIP for captioning the entire clip. Finally, using some standard LLM these captions are summarised to arrive at the final caption for a given clip. The size of this dataset turns out to be 580 million clips along with their captions.
They called this dataset the Large Video Dataset or LVD in short.
In addition to the cut detection pipeline, they use several other filtering such as optical flow scores, synthetic captions, OCR detection rates, and aesthetic scores to finally narrow down this dataset to just 152 million and call it LVD-F.

Optical flow. For the optical flow, they calculate the optical flow score between sequential frames (as shown above) in the clips and eliminate those clips that are below a threshold which indicates that there is no sufficient motion in the clip.

Synthetic captions. The need for synthetic captions is that the given dataset is too large to be fully manually captioned. So they use LLM models to synthesize captions from image and video captioning systems. In this example sequence, CoCa the image captioning system says, “There is a piece of wood on the floor next to the tape measure”. The video captioning system V-BLIP says, “A person is using a ruler to measure a piece of wood”. Finally, the LLM combines the two captions and comes up with the synthetic caption, “A person is using a ruler to measure a piece of wood on the floor next to a tape measure”.
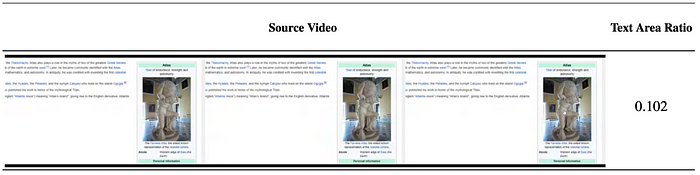
OCR. As the data is collated from the internet, they are quite likely to have a lot of text. For example, the Wikipedia image shown above has several text descriptions that are not too helpful when it comes to training for video generation. So Using OCR algorithms, they compute the area of the text relative to the image (0.102 in the above image) and eliminate those clips that have a large text area.
Aesthetics score. Finally, the aesthetics score is all about how appealing the images in the video clips are to the annotator
With all those scores, we finally arrive at the 4 variations of the dataset as shown below.
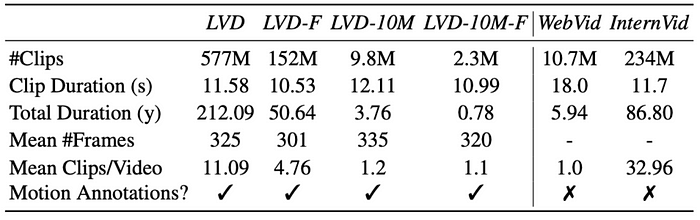
The LVD dataset is the raw dataset that they collected. Applying filters that we just saw leads to LVD-F with just 152 million clips left in the dataset. They have also done random sampling on the LVD dataset to arrive at a subset of the dataset which is just 10 million clips and call it LVD-10M. Applying the filtering process to these clips results in only 2.3 million clips which they use for different experiments and ablation studies. This dataset goes by the name LVD-10M-F.
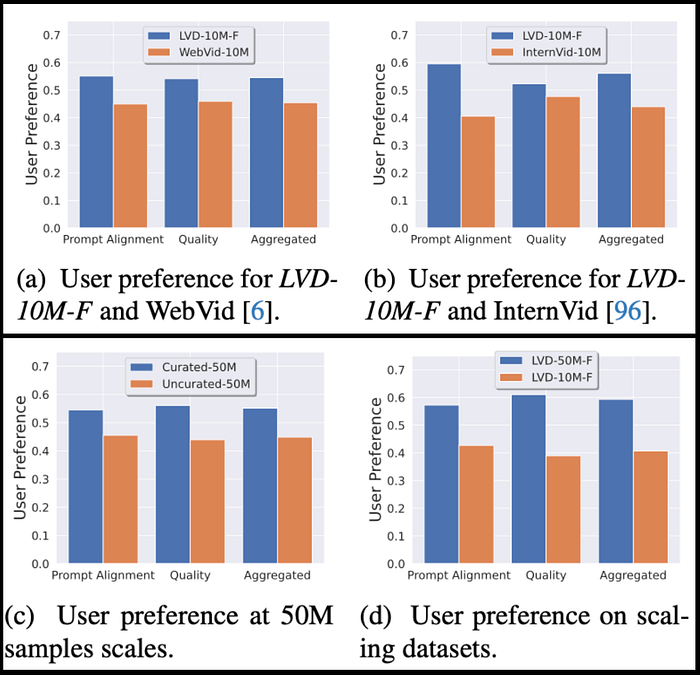
In the first ablation study, they studied the impact of the curated dataset LVD-F. The only way to know its impact is to compare it with datasets that are not curated such as WebVid and InternVid. The results indicate that pretraining on curated datasets consistently boosts the performance of generative video models during video pretraining. Even at a large scale of 50 million samples as seen in the bottom plots in the figure above, curation seems to help.
High-quality fine-tuning
Moving on to the third and last stage of high-quality fine-tuning, they draw on training techniques from latent image diffusion modeling and increase the resolution of the training examples.
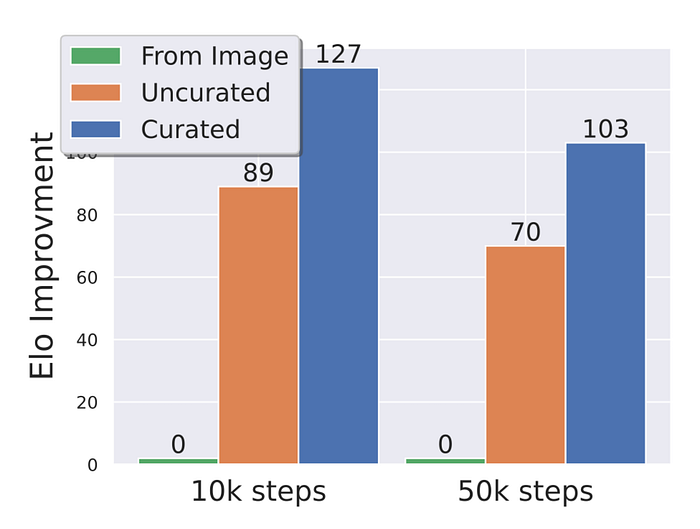
They again compare three models (as shown in the figure above), one with just the image pretraining, and the next two models with video pre-trained with and without the curated dataset. We can see that we not only need video pre-training, but we also need the dataset to be curated.
With these results, they conclude two things. i) the separation of video model training into video pre-training and video fine-tuning is beneficial for the final model performance after finetuning and ii) video pre-training should ideally occur on a large scale, curated dataset”
Base Model and Real-world Results
They create the base model in two steps. In the first step, they train using the filtered dataset on 14 frames at a resolution of 256 × 384 and train for 150k iterations at a batch size of 1536. In the fine-tuning step, they increase the resolution to 320 × 576 but decrease the batch size to 768, and run for 100k iterations.
It's this base that they use to generate videos for all sorts of applications like image-to-video, text-to-video, and video-to-multi-view 3D outputs as below.


Finally, for image-to-video, the input conditioning is an image. So they replace text embeddings that are fed into the base model with the CLIP image embedding of the conditioning.

To show that SVD is versatile and it's possible to control the camera motion, they replace the camera motion LoRA with temporal attention blocks from stable video diffusion. The three rows correspond to horizontal, static, and zoom.

They also fine-tune a new model for multi-view generation and name it the SVD-MV model. In this case, the model takes as input a single image and outputs multiple views of the same object in the image as shown in the image above and also on the SVD blog page.
Conclusion
This work has clearly shown that video generation pipelines need to be 3 stages rather than two stages as understood so far by the community. The new stage is the pre-training for videos rather than just pretraining for images.
As with few other recent works such as Emu for image generation, this work also insists that it's not just quantity (scale) but the quality of the curated video for the pre-training dataset that matters to produce the best results
What would have been nice to see is the open sourcing of the dataset or release of the dataset they have curated. But as far as I can see, only the weights of the trained models are released.
Hope that was useful. I will see you in my next post. Take care!