LoRA - Low-Rank Adaptation of LLMs (paper explained)

Introduction
Whenever we want a custom model for our application, we start with a pre-trained language model and fine-tune it on our dataset. This used to be fine until we reached the Large Langage Model regime and started working with models such as GPT, LLAMA, Vicuna, etc. These LLMs are quite bulky so fine-tuning a model for different applications such as summarization or reading comprehension needs deploying the model for each application.
and the size of these models is only increasing almost on a weekly or monthly basis. So the deployment of these bulky LLMs is getting increasingly challenging.
One solution proposed for this problem is adapters.
Adapters are trainable additional modules plugged into the neural network (mostly transformers). During fine-tuning, the parameters of only these adapter modules are updated with the pre-trained model frozen.
Because adapters are additional parameters, they introduce latency during inference. For a fixed batch size of 32 and sequence length of 512, 0.5 a million parameter model takes 1449 milliseconds for inference. But with adapters, it's 2 to 3% higher.
So, How does LoRA achieve this feat? Let's dive deeper.
Visual Learning
If you are a visual learner like me and would like a video version of this article, you may find it on YouTube:
LoRA
LoRA stands for Low-Rank Adaptation. So what does that mean?
For any neural network architecture, let us not forget that the weights of the network are just large matrices of numbers. All matrices come with some property called the rank. The rank of a matrix is the number of linearly independent rows or columns in a matrix
To understand it let's take a simple 3 by 3 matrix.
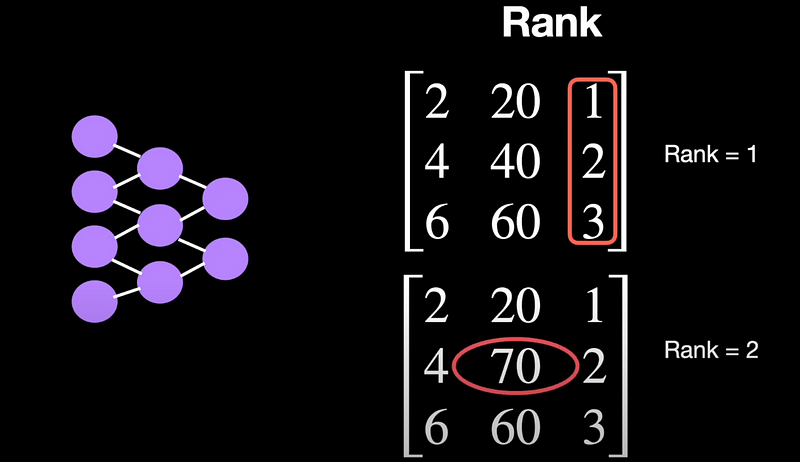
The rank of the simple 3 by 3 matrix at the top is 1. Why? because the first and second columns are redundant as they are just multiples of the first column. In other words, the two columns are linearly dependent and don’t bring any meaningful information. Now, if we simply change one of the values to 70, the rank becomes 2 as we now have two linearly independent columns.
Knowing the rank of the matrix, we can do “Rank Decomposition” of a given matrix into two. Going back to our example 3 by 3 matrix, it can simply be written as the product of two matrices one with the dimension 3 by 1 and the other with the dimension 1 by 3.

Notice that we only have to store 6 numbers after decomposition instead of the 9 numbers in the 3 by 3 matrix. This may sound less but in reality, these weights have a dimension of 1024 by 1024 and so using a rank of 2, it boils down to < > which is a lot of reduction in computation.
So would it not be nice if these weights have a low rank so that we can work with rank decomposition instead of the entire weights?
It turns out that indeed is the case of pre-trained models as shown by this earlier work. They empirically show that common pre-trained models have a very low intrinsic dimension; in other words, there exists a low dimension re-parameterization that is as effective for fine-tuning as the full parameter space.
Training

Let us say we are starting with a pre-trained model with weights W_0. After fine-tuning, let the weights be updated to W_0 + delta W. If the pre-trained model has low-rank weights, it would be a fair hypothesis to assume that the fine-tuned weights are also low-rank. LoRA goes with this assumption. Because delta W is a low-rank, we can now decompose it into two low-rank matrices, A and B whose product BA leads to delta W. Lastly, finetuning becomes the pre-trained weights W0 + BA instead of W_0 + delta W as it is one and the same.
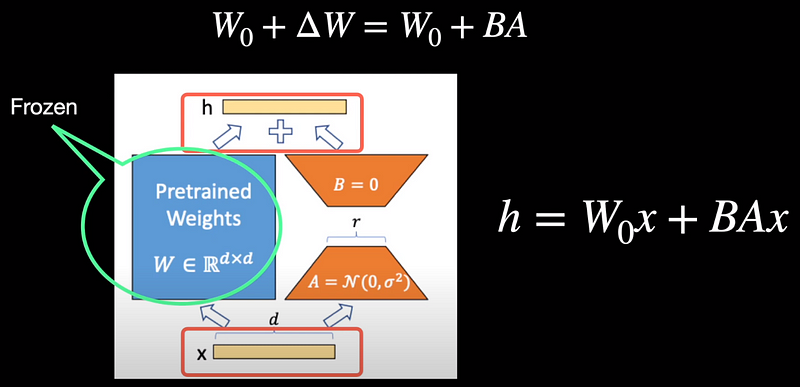
With that perspective, if we start training the model, with input x, the input passes through both the pre-trained weights but also through A and B. The weights of the pre-trained model remain frozen. However, we still consider the output of the frozen model during training. The output of both the frozen model and the low-ranked model are summed up to obtain the output latent representation h.
Inference
Now you may ask, what about latency during inference? If we slightly modify the above equation, we can notice that we can merge or add the weights BA to the pre-trained weights W_0. So, for inference, it is this merged weight that is deployed thereby overcoming the latency bottleneck.
One of the other concerns is the deployment of LLMs as they are quite bulky, say about 50 or 70 GB. Let us say we have to fine-tune for two tasks namely, summarization and translation. We don’t have to deploy the entire model every time we fine-tune. We can simply fine-tune the loRA layers specifically for the task. For example summarization. and deploy the model for summarisation. Similarly, we can deploy LoRA layers specific to translation.
Thus LoRA overcomes both the deployment and latency problems faced by modern-day LLMs.
LoRA for transformers
In terms of applying for transformers, we all know that the transformers have two main modules which are multi-headed self-attention and the multi-layer perceptrons or MLPs. The self-attention modules are composed of query, key, value, and output weights. So they have limited their study to only adapting the attention weights for downstream tasks and freezing the MLP modules (so they are not trained in downstream tasks). This means that LoRA is just applied to the self-attention module.
We have been talking about using LoRA for adaptation. One of the key parameters in LoRA is the rank, r which we choose. So what is the optimal rank for LoRA? It turns out, to everyone’s surprise, a rank as small as 1 is sufficient for adapting both the query and value. However, when adapting a query alone, it needs to have a larger rank of 4, 8, or even 64.
Using LoRA
Moving on to how we can practically use LoRA, there is the official implementation from Microsoft which is released as loralib and is available under MIT license.
Another option to use LoRA is the huggingface repo called PEFT which stands for parameter efficient fine tuning. PEFT is available under the Apache 2 license. PEFT has a few other implementations such as prefix tuning, and prompt tuning, and LoRA is one of the earliest implemented in the library.
Conclusion
LoRA is a simple but effective fine-tuning approach that lays the foundation for PEFT of LLMs. It enables both the training and deployment of powerful models on commodity hardware which otherwise is not an easy feat. What not, there are several variations or improvements to it such as QLoRA which we will cover in my upcoming articles.
I hope this article was useful in understanding the functioning of the LoRA model. I hope to see you in my next. Until then, take care…