QLoRA — Train your LLMs on a Single GPU

In my previous article, we saw about Low-Rank Adaptation or LoRA. LoRA is quite effective for deploying large models and is also fast for inference, thereby solving the inference problem of fine-tuned LLMs. However, when it comes to training, LoRA doesn’t do the trick. For example, to fine-tune a LLAMA 65 billion parameter model, LoRA needs 780 GB of GPU memory. That is about 16 A40 GPUs. The answer to this problem lies with QLoRA where Q stands for Quantisation. The main motivation for QLoRA is to achieve fine-tuning on a single GPU.
QLoRA does this with only three innovations namely:
1. 4-bit NormalFloat (NF4), a new data type that is information-theoretically optimal for normally distributed weights
2. Double Quantization to reduce the average memory footprint by quantizing the quantization constants,
3. Paged Optimizers to manage memory spikes.
In this article let's look at all three of these novelties and understand QLoRA.
Visual Learning
If you are a visual learner like me and would like a video version of this article, you may find it on YouTube:
Quantization
Let's start with Quantisation which is fundamental to QLoRA. Simply put, quantization works by rounding and truncating to simplify the input values.
For the sake of simplicity, consider we are quantizing from Float16 to int4. Int4 has a range of -8 to 7. As we only have 4 bits to work with, we can only have 2 power 4, which is 16 bins to quantize into. So any input float value needs to be mapped to the centers of one of these 16 bins.
Getting into neural networks, the inputs are tensors which are large matrices. And they are usually normalized between -1 and 1 or 0 and 1. Let's consider the case of a simple tensor with 3 values, say, -0.976, 0.187, and 0.886. We are lucky with this example as the values are distributed equally across the normalized range. When we quantize to int4, each of the 3 numbers takes a unique bin.
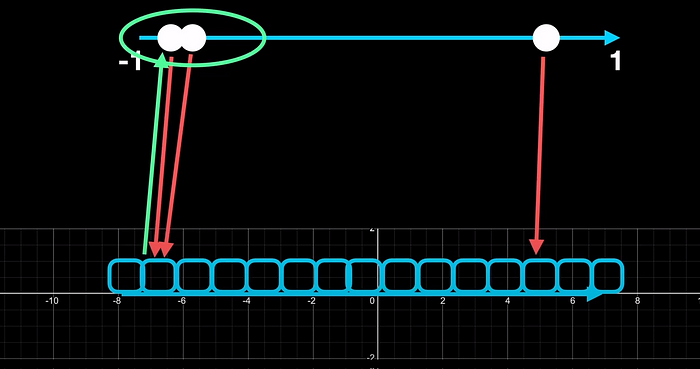
Let's take a slightly different example where the input values are no longer equally distributed in the input range. Let two inputs be close together, with one far apart. If we now quantize to int4, the first two numbers fall in the same bin. while the third one is fine. Oh, we don’t want this because, if at all you want to dequantize and convert back to float16, the two numbers no longer convert back to unique values. In other words, we lost valuable information through quantization error.
Blockwise Quantization
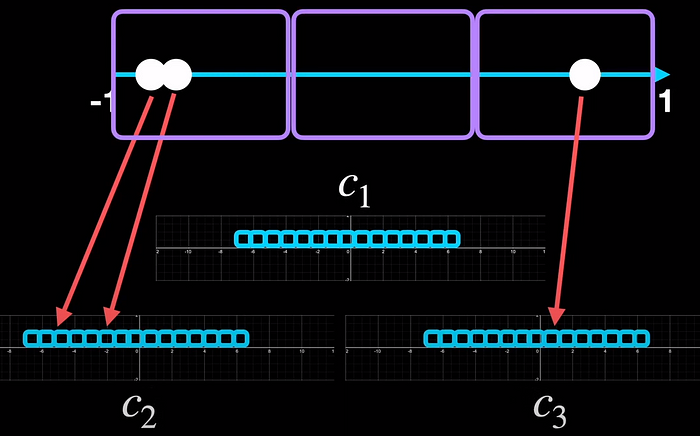
One way to overcome this problem could be to divide the input range into separate blocks. In this example, we have three blocks. And we quantize each block separately with each having its own range. So now, the two values that are close together find different bins inside a block. And the third one never had a problem so it's fine.
By dividing into blocks, we independently quantized each block and so each block comes with its quantization parameters, which often is the quantization constant c. In this example, they are c_1, c_2 and c_3.
What we just saw is block-wise quantisation which we illustrated with three blocks.
But practically QLoRA uses a block size of 64 for the weights for high quantization precision.
NormalFloat
Talking of the weights, one of the interesting properties of pre-trained neural network weights is that they are normally distributed, and centered around zero.
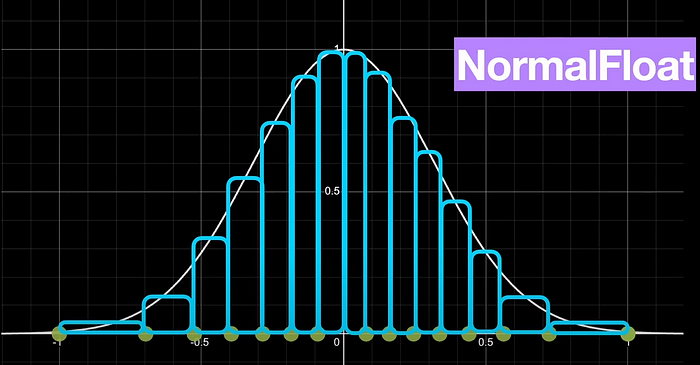
This means that there is a very high probability for values occurring closer to zero rather than around -1 or plus 1. But our standard quantization to int4 is not aware of this fact. And so goes by the assumption that each of the 16 bins has an equal probability of getting the values.
To address this problem with standard quantization, we can develop a slightly specialized type of quantization that considers the normal distribution of the neural network weights. This is exactly what QLoRA does and it names it k-bit NormalFloat. In NormalFloat, the bins are weighted by the normal distribution and hence the spacing between two quantization values are far apart near the extremes of -1 or 1 but are closer together as we get closer to 0.
To throw some additional light, the green dots show the 4-bit NormalFloat quantization versus the standard 4-bit quantization shown in the blue dots.
Let's now move to the next contribution of the paper which is double quantization.
Because the motivation of QLoRA is to train on a single GPU, it is essential to squeeze every bit of memory as possible. If we recall blockwise quantization, we saw that we use 64 blocks to quantize the weights and each of these blocks has a quantization constant *c*. So double quantization is the process of quantizing the quantization constants for additional memory savings. And through double quantization, we gain half a bit per parameter on average.
The last bit of the puzzle is paged optimizers.
Paged Optimizers

Paged Optimizers prevent memory spikes whenever we abruptly get a long input. Let's say we are working with documents and suddenly we have a long document. When we use a single GPU for training, this spike in sequence length generally breaks the training. So to overcome this, the state of the optimizer, say Adam is moved from the GPU memory to the CPU till the long sequence is read. Then when the GPU memory is freed, the optimized state is moved back to the GPU. At a high level thats what happens if we leverage paged optimizers.
In terms of the implementation, the paged optimizer is part of the bits and bytes library. and you can enable or disable it during your QLoRA training by simply setting the flag is_paged on or off.
Putting together the above-mentioned three components, QLoRA efficiently uses a low-precision storage data type, in our case usually 4-bit, and one computation data type that is usually BFloat16.
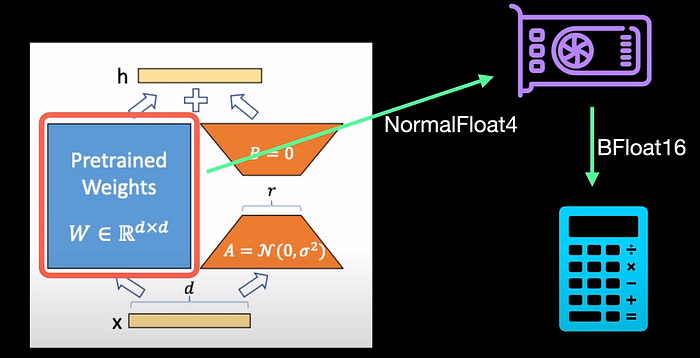
What does that mean? Going back to LoRA, it means that to optimize for the memory, the weights of the model are stored in NF4. This enables us to load the weights into a single GPU and the loaded weights are converted into BFloat16 for the computation of gradients during backpropagation.
To link it to LoRA, let's look back at this equation from LoRA where x is the input, and W_0 is our pre-trained model weights. A and B are low-rank matrix decompositions.

With QLoRA, our input x is BrainFloat16. Our weights are stored as Normal Float4 (NF4). During the computation of gradients, our weights and quantization constants go through a double dequantization which is the reverse of double quantization. It happens by first dequantizing the quantization constants, c_1 and c_2. Then using the constants, we once again dequantize the weights to BrainFloat16 which is used to compute the gradients.
If you are wondering how good is NormalFloat and double quantization, the authors of QLoRA experimented with four datasets and showed that in all four cases using normal float and double quantization improves the mean zero-shot accuracy of training compared to simply using float.
In terms of the GLUE score, QLoRA can replicate the accuracy of 16-bit LoRA and full-finetuning. The authors conclude that 4-bit QLORA with NF4 data type matches 16-bit full finetuning and 16-bit LoRA finetuning performance on academic benchmarks with well-established evaluation setups.
So if you are interested in finetuning on a single GPU and would like the fine-tuned model to match the performance of standard finetuning on multiple GPUs, then QLoRA is the way to go.
I hope that was a useful insight into QLoRA. I will see you in my next. Until then, take care.