Fine-tuning of LLMs - The six step lifecycle

Fine-tuning is an art and a methodical process similar to software engineering. It is extremely simplified and portrayed as a cakewalk in some recent blogs and vlogs. So, in this article, I have elaborated on what it takes to go from a pre-trained model to a fine-tuned model ready for production. This is a high-level overview. I will be diving deeper into each of these steps with hands-on in my upcoming articles.
Motivation
Whenever we are given a pre-trained model such as llama 2, in most cases it is sufficient with a bit of prompt engineering. Prompt engineering is all about cleverly constructing the query to the LLM. Good prompts get far better responses from LLM than ordinary prompts. For example, if I ask the model, “What are the qualities of a good model”, it assumes I am asking about a fashion model and comes up with an answer listing physical attributes, confidence, professionalism, adaptability, etc. But if I provide some context by prompting, “What are the qualities of a good LLM model”, it now responds with the answer I was expecting and says “large vocabulary, contextual understanding, fluency, consistency”. This is a naive example of prompt engineering.
In another example, if we ask LLAMA 2 a domain-specific question, “How long is the current inflation likely to last”, it gives a factual response with the different inflation scenarios such as short-term inflation, moderate inflation, higher inflation and hyperinflation without actually answering my question.
It is these scenarios that indicate that the model is lacking an expert-level skill in a particular domain. It is at this point you will have to think about fine-tuning.
Visual Explanation
If you would like a visual explanation of this article, it is available as a video below:
So what is fine-tuning?
Fine-tuning is when you modify the pre-trained LLM by updating its parameters. Fine-tuning is useful if you want to make the LLM an expert in a specific domain such as medicine or if you want to make the model much more specialist in a specific task of your liking such as a conversational AI or reasoning. As a result, we get a proprietary, in-house model for the particular task or problem that your organisation is uniquely solving using the data available at its disposal.
Advantages of fine-tuning
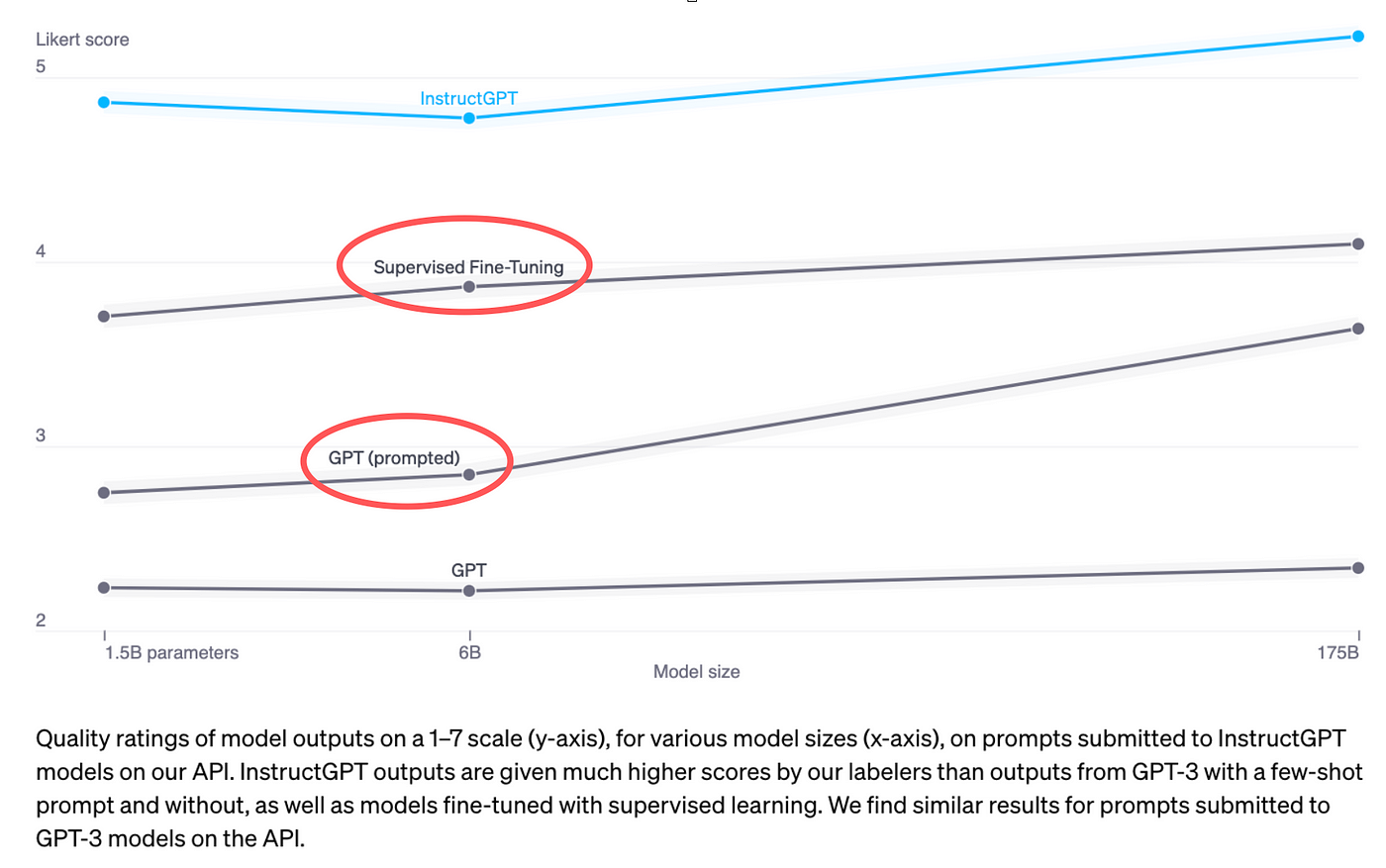
- fine-tuning generally improves the model performance. It was clearly shown in the Instruct-GPT paper (in the below figure) that GPT-3 with supervised fine-tuning showed better performance compared to simply prompt engineering. These are based on the scores given to the model output on a scale of 1 to 7 by human labellers.
- The second advantage of fine-tuning is to do with storing, deploying and serving these LLMs. In the past few years, there has been an exponential increase in the size and computation of the LLMs leading to high demand for ways to store, deploy and serve these models. To solve these problems, fine-tuning is the answer. For example, a fine-tuned LoRA is very lightweight and deploying it becomes a piece of cake.
The six-steps
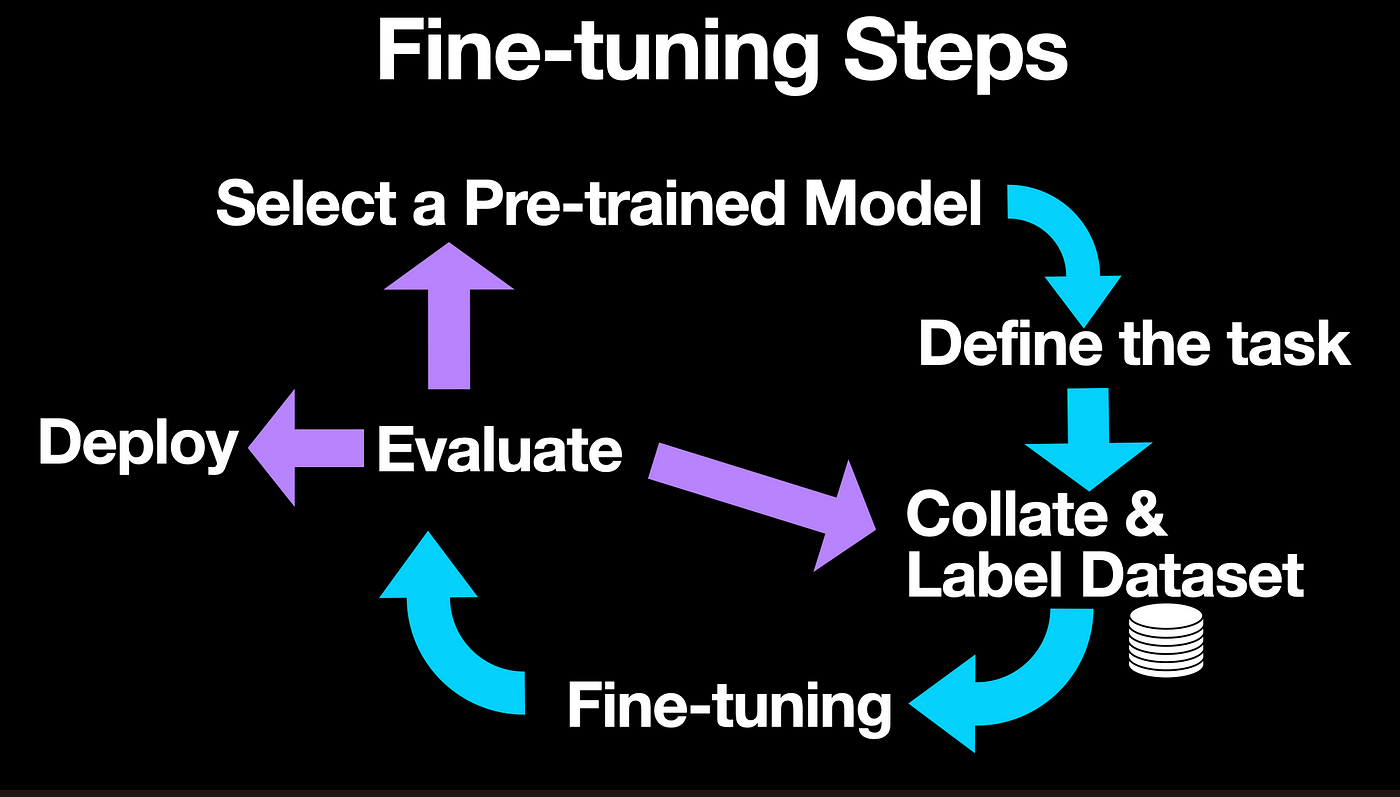
Below are the six steps involved in fine-tuning a pre-trained model.
Select a pre-trained model
Below is an overview of the six steps organizations have to follow to take a pre-trained model, fine-tune it and deploy it in production.
The first step involved in fine-tuning is selecting a pre-trained model. For this, we have a wide array of models like LLAMA2, Vicunna, and Alpaca. Even though they are all classed as open-source LLMs, different models do well at different tasks.
For example, the RoBERTa model developed by Meta was specifically designed for text classification tasks. And so, if you want to do sentiment analysis, then you are better off choosing this rather than using LongFarmer which is a specialist model if you have a long context length.
Define the task
The second step towards fine-tuning is, defining the task based on the problem at hand. For example, if you are a law firm and the work involves reading pages and pages of documents, then you may want to fine-tune for summarization of your documents. So your task is summarization!
Before deciding to move on with the next step, you might as well want to ensure that there is sufficient data to feed the LLM beasts. To avoid overfitting, you might have to ensure that you have hundreds of thousands of data points for the given task.
Collate and label data
The third step and the most labour-intensive process for fine-tuning is collating a dataset. At this stage, all the data that you have gathered in the previous stage will go through labelling. Labelling can be very quick or very time-consuming depending on the task you have chosen.
For example, if your task is sentiment classification, the labellers can get away with simply clicking the buttons positive or negative. If your task is summarisation, it could be quite time intensive with the labellers even writing the summaries of documents. Though this step is labour-intensive, you end up with an in-house dataset that is unique to you and only your organization. It can be a huge selling point to your customers to show these datasets and models trained with them.
Fine-tuning
The fourth and exciting step is the actual supervised fine-tuning of the pre-trained LLM. All the labelled data from the previous stage now goes to the techies who are often ML engineers or developers who work on finally writing the code to finetune the pretrained LLM.
Though this step may involve only a few lines of coding, it can be quite challenging to tweak hundreds of training parameters to get the training to converge and produce a successful finetuned model. So, this step may involve extensive experimentation and so can take quite some time.
As a simple example, you may have to train one model with a learning rate of 0.01 and another with a learning rate of 0.05. There are tons of optimizers and choices for data augmentation. Playing around with all these parameters is an art in itself and is often the job of a machine learning engineer.
In any case, if you are expecting a finetuned model, in the first run of the training, you simply got it wrong. It's more involved than that. This leads to the question, “How do you even know if your fine-tuned model is any good?”.
Evaluation
And so the next step in finetuning is the evaluation of the fine-tuned model. First, you need to choose what metric you are concerned about. And to a large extent, this depends on what the customer exactly wants.
For example, if you are doing sentiment classification, the most important metric most people worry about is the accuracy of classification. But if you are building conversational bots, then the metric for your evaluation would probably be the F1-score.
But remember, the customer is God. So the ultimate evaluation for your chat model would be a decrease in the decrease of escalation to first-level calls, conversion rate, email reduction rate, etc.
With metrics, there is always the challenge of mapping the technical evaluation score such as F1-score to the business scores such as conversion rate and escalation rate. How to tackle this challenge opens up a completely new chapter for debate and is not a topic for today’s discussion.
The result of the evaluation can take you in one of three directions. First is deployment, which indicates that you are satisfied with the results and would like to see your model in production.
The second is collating more data. This is indicated by overfitting which is quite common for large models. Overfit models just memorize the training data and churn out the memorized text. Another indication that your model is overfitting is that the evaluation metric on your training data will be super high and the metric on your evaluation set will be quite low. When you see that your model does well on the training data but does poorly on the evaluation data, you know you need more data.
Or you may go back and look into the pre-trained model you have chosen and decide to choose a smaller model or a completely different model.
To get the latest and greatest AI research news from top AI labs, why not follow me on Twitter
Concluding remarks
In my opinion, the above six steps form the typical lifecycle of a model that goes all the way from pre-trained to deployed state in production.
In the upcoming articles let's do a hands-on to see how we can fine-tune an open-source model using a colab notebook.
So please stay tuned and I will see you in my next. Until then, take care…