Retrieval Augmented Generation(RAG) — A quick and comprehensive introduction

LLMs have come a long way in the past year or so. Though we are continuing to see huge progress almost every week, three problems are being addressed by the current research community.
- One is hallucinations where the LLM receives queries extended beyond the model’s training data and so the model comes up with imagined answers
- Second is outdated knowledge where the model is not aware of some domain-specific information or events that happened after the point in time the model was trained
- third is reasoning capability which almost every LLM is limited with
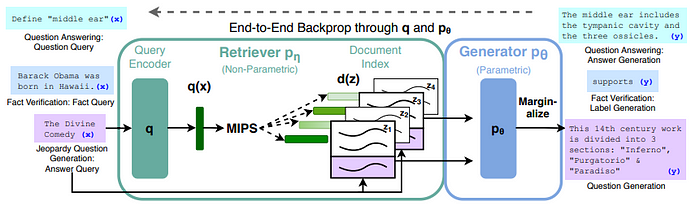
RAG which stands for Retrieval Augmented Generation tries to address both outdated knowledge and hallucinations. It was introduced not long ago in 2020 in this paper titled, “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks” [1]. They proposed to combine a pre-trained retriever along with a pre-trained seq2seq model which is a Generative model. And showed that combining them both leads to better performance of the generative model.
So let's dive into Retrieval Augmented Generation or RAG.
Visual Explanation
If you would like a visual explanation of this article, there is a YouTube video.
So, What is RAG
If you take a standard LLM, the user interacts or queries using a prompt and the LLM gets back to the user with a response. This is fine as long as the LLM has an answer. But if the query is alien to the LLM, it starts making up answers similar to how we start guessing answers when we write exams.
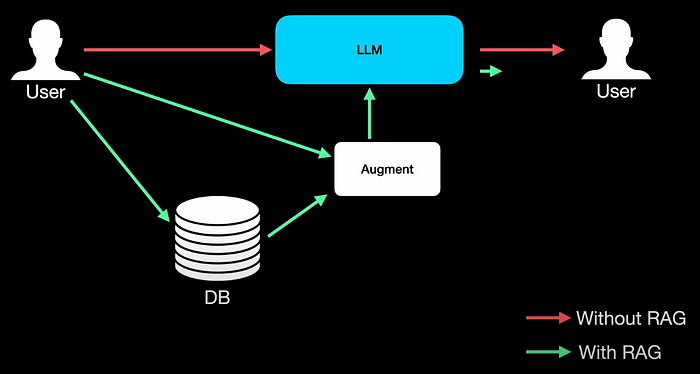
With RAG, we introduce a database of knowledge, and every time the LLM receives a request, the database is queried and the data retrieved from the database is then augmented to the prompt from the user by some means, and the augmented or combined input is fed to the LLM which in turn responds, this time with much more contextual information.
This way of providing additional context seems to firstly reduce hallucination because the LLM gets much more contextual information about the user’s prompt and the information in the database can bring in up-to-date information.
Clearly, there is retrieval from a database augmentation of the input prompt with additional information and there is the generation of output from an LLM, making it a retrieval-augmented generation. Obviously, we overly simplified what goes on under the hood. For example, there is indexing, embedding, chunking, searching, and many more things going on. Putting them all together forms the RAG framework.
Let's dig deeper into the RAG framework and understand each of the elements now.
RAG framework
It all starts with external data or knowledge that can be in form such as PDF, HTML, markdown, or Word document.
Whatever the format, indexing is the process of cleaning and converting these formats into standard text format.
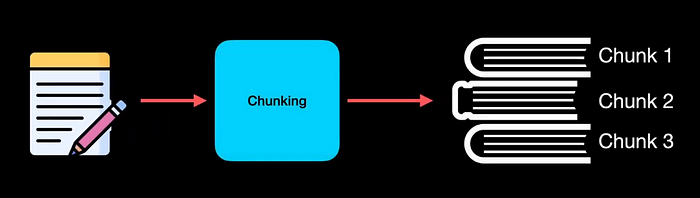
LLMs have something called the sequence length beyond which they cannot take the input data anymore. For this reason, the cleaned text data from the previous step goes through chunking. Chunking is the process of dividing the text into equal-sized data. In this example, the input text is divided into three chunks.
These chunks are then passed through an embedding model. The output of the embedding model is a list of numbers of fixed length which are also called embeddings or vectors. Let's fix the length of these vectors to be 3 in our example. So let's say chunk 1 got embedded into values 0.1, 0.2, 0.3.
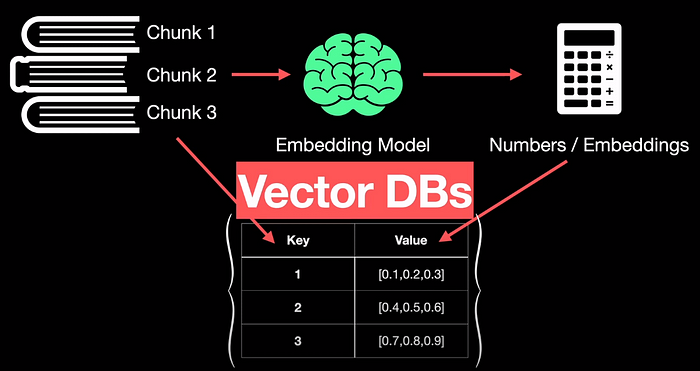
Similarly, each chunk can be vectorized to get its corresponding vectors. the mappings between these vectors and their chunks are stored as key-value pairs in a database. These databases have a special property compared to traditional Online Transaction Processing or OLTP databases. So, these are referred to as vectorDBs.
This sequence of steps such as cleaning, chunking, and embedding is referred to as indexing.
Indexing has led to the creation of data in the vector database in our RAG framework. Once we have this database, whenever a user queries or prompts, the query is passed through the same embedding model we used during indexing so that the query gets embedded into vectors.
We then run a similarity search and compute a similarity score between the query vector and the vector chunks stored in the DB, to retrieve or fetch the top K answers, which are top-3 in this example that are most similar to the input query. The results are sorted from the most similar to the least similar. In this example, even though chunk 1 with values 0.1, 0.2, and 0.3 seems to be the most similar to the query, the top-3 results are returned as per the setting. This process is called retrieval.
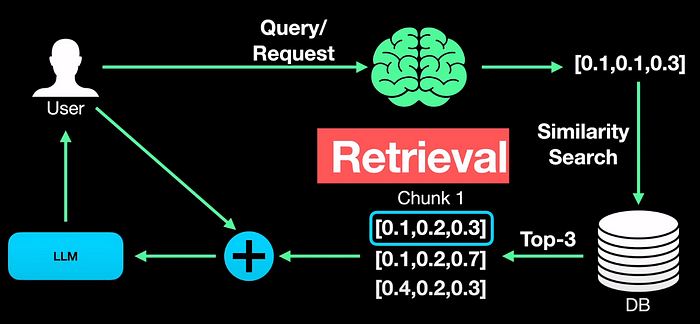
These retrieved chunks provide additional context to the LLM. So needs to be combined with the user prompt. This process is combining the retrieved knowledge with the prompt is referred to as augmentation. The augmented query is then fed to the LLM to generate a response. Augmentation can be as simple as just adding the retrieved text to the end of the prompt.
A simple Example
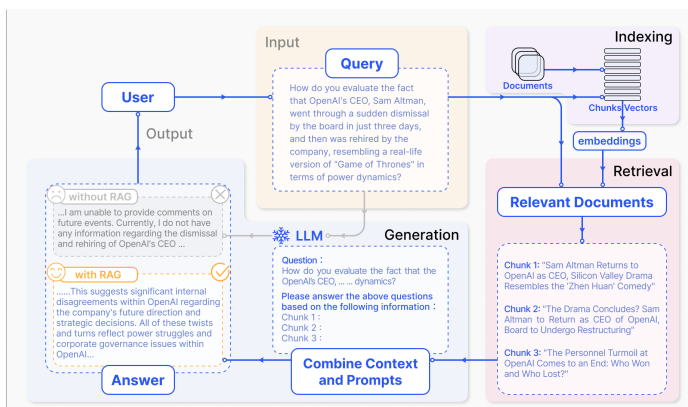
Now let's look at an example to understand the simple RAG workflow. For this, let's consider the well-known Sam Altman’s story of his dismissal and reinstatement from OpenAI.
Without RAG. The user asks a question or the user prompt or query is, “How do you evaluate the fact that the … “. As the LLM was trained before this news event, it responded by saying, “I am unable to provide … “, as shown in the figure above.
With RAG. With RAG, what happens is all the relevant documents such as the news stories, get indexed using the cleaning, chunking and storing process outlined earlier.
Whenever the system gets a new query/prompt from the user, the relevant information is then retrieved from this vector DB, in this case and a pre-defined set of results (the top-3 chunks in the example) are returned for augmentation. The three chunks are combined with the user prompt by just adding one line saying, “Please answer the above question based on the following information”.
This finally leads to the LLM answering, “This suggests significant internal disagreement within OpenAI… “ which is far better than simply declining to answer.
So that is how we enrich an LLM with information from an external system by retrieving and augmenting the generation process by simply adding a database.
One of the beauties of RAG is that you don’t have to deal with training or fine-tuning the model. But some situations put you in a position to finetune the model.
Let's look into that in our next video. Until then, I am signing off and I will see you in my next. Take care…
References
[1] Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela, Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks, (2021), arXiv preprint.
[2] Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Qianyu Guo, Meng Wang, Haofen Wang, Retrieval-Augmented Generation for Large Language Models: A Survey, (2023), ArXiv preprint.