LLMs Reasoning is an Illusion!

At least that is what the latest findings from Apple Research indicate
We all are quite familiar with Large “Language” Models (LLMs) by now. But in the recent past, we have seen Large “Reasoning” Models (LRMs) surface. Whenever we prompt an LLM, we have the ability to make it “think” and, hence, reason and provide a more clever response. This is the reason we see some reasoning “traces” when some models are running.
The limitations of these LRMs are insufficiently understood. Primarily because the benchmarks are limited to evaluating the mere outputs of models. For example, we have some well-known benchmarks like Math-500 or AIME24 and AIME25. We even have public leaderboards that compare and rank all state-of-the-art models. However, these benchmarks and leaderboards evaluate the LRMs based on the end result.
There is a new paper in town called “The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity”, from Apple Research. The argument is fairly simple:
- Why evaluate reasoning models on benchmarks? Instead, evaluate their intermediate thought process. This is possible if we give them controlled puzzles for which the intermediate results can be evaluated or validated.
- Furthermore, the evaluation datasets have data contamination because of which evaluation is not accurate. So why use them in the first place!?
Following this argument, they have also published some findings:
- LRMs experience a tipping point or accuracy collapse. Beyond this point, they sometimes can NOT solve a given problem irrespective of computing budget or token length
- The experience scaling limits because of the above findings.
Puzzles for Evaluation
The good thing with puzzles is that:
- We can increase the complexity of the puzzles gradually.
- They can be solved step by step. So the LRM reasoning can be examined far better than asking it to solve a huge math equation.
- We can introspect the middle state or the “thinking” state of these models while solving the puzzles

For this reason, they have used 4 puzzles to evaluate LRM reasoning ability — Tower of Hanoi, Checkers Jumping, River Crossing, and Blocks World.
With these puzzles, they were able to increase the complexity of the puzzles gradually. For example, in the checkers game the complexity increases as the number of checkers n increases. Similarly, they have increased the complexity of all 4 puzzles and published the results of their findings.
Models for Experiments
They have used the deepseek R1 and Claude 3.7 Sonnet thinking for their experiments. They weren’t able to choose OpenAI’s models as OpenAI does not reveal the intermediate reasoning tokens during the thinking mode.
Complexity of Reasoning
Based on the performance of the models, they have established 3 regimes of reasoning:
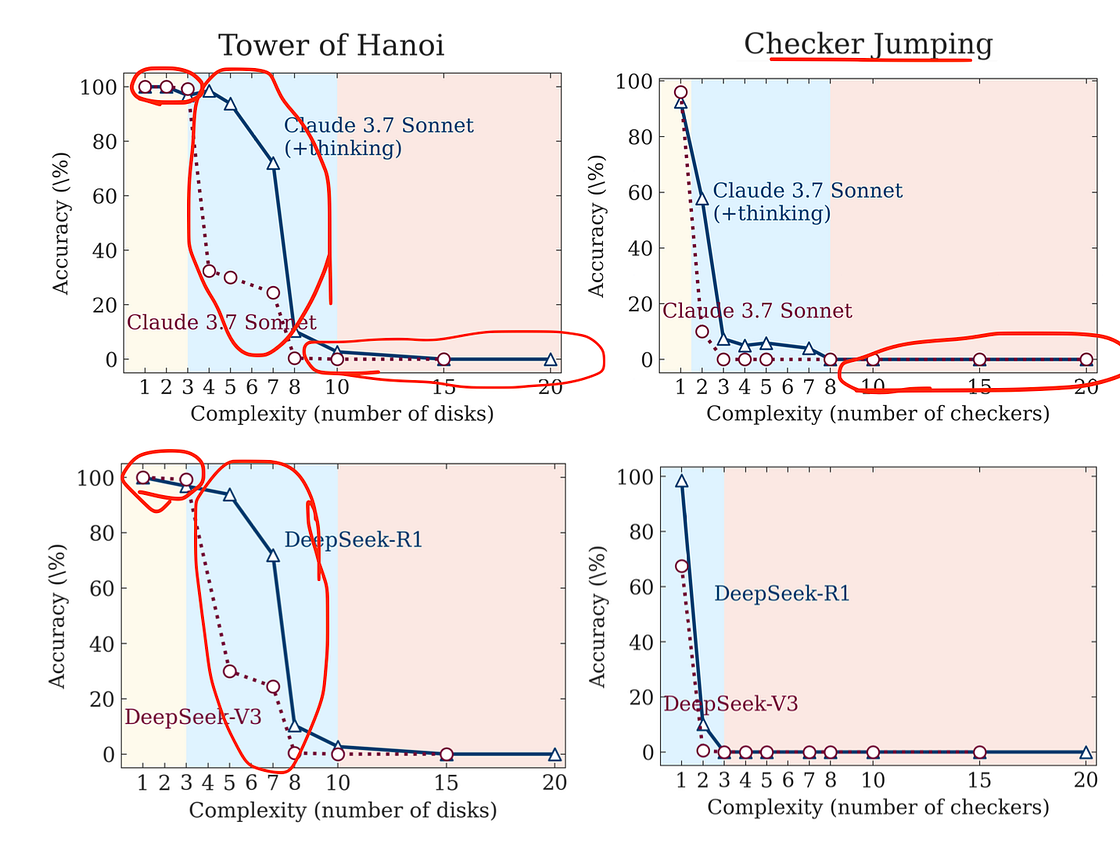
- First Regime. In this regime, both the non-thinking and thinking models are on par in performance. If anything, the non-thinking models are better than the thinking models. This is shown as a yellow region in the plot above.
- Second Regime. The second regime is where the actual power of thinking or reasoning models is leveraged. As we increase the complexity of the puzzles a bit more, the thinking models show better performance compared to the non-thinking models. It is shown as a blue region in the plot above.
- Third Regime. This is where all models collapse. As we increase the complexity of the puzzles even more, both the thinking and non-thinking models cross a tipping point beyond which they cannot solve the problem. This surprising behavior can be observed in all models! It is shown in the red region in the plot above.
Inspecting the thought process
Working with puzzles enabled them to inspect the thought process of the models in detail. The intermediate moves or states of the puzzle-solving steps were fed to puzzle simulators for validation of the moves.
The findings include:
- For simple puzzles, the models arrive at the solution quite early but still keep thinking about solutions.
- For complex puzzles, they take time to arrive at a solution, making the most of the thinking time or tokens.
- As the complexity is increased even further, they start collapsing irrespective of the computing budget.
Results with Algorithm
This is equivalent to an open-book test. The models were given the algorithms in the prompt to solve the puzzles. One will expect the performance to shoot upwards. One will also expect to prevent the collapse by doing so. But surprisingly it doesn’t seem to be the case as shown by the below plot:
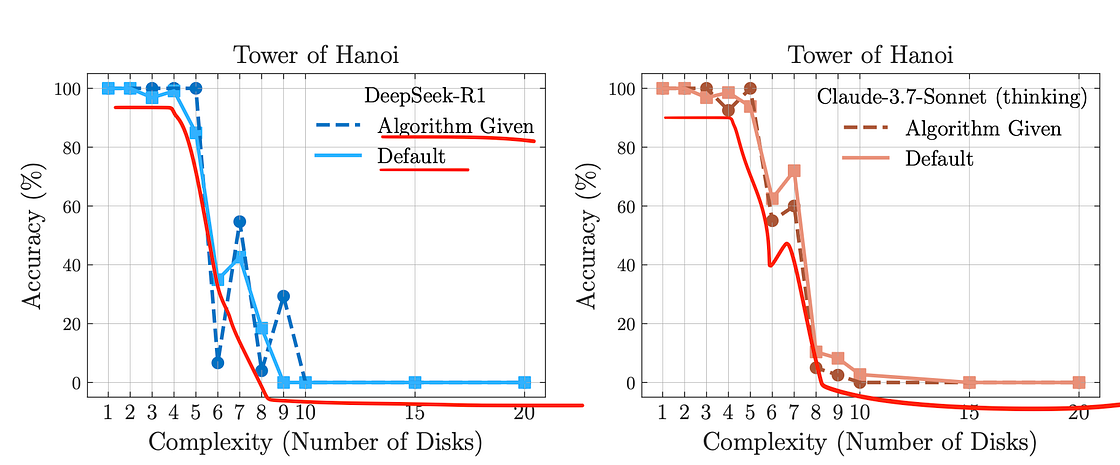
The performance before and after providing the algorithm remains the same. The model is not able to reason and use the algorithm to improve its answers.
So, is reasoning an illusion?
The above finding leads to the question, “If the model is not able to reason even after being provided with the algorithm, is it even reasoning?” It's quite likely that the model is simply memorizing the training data and simply churning out text based on its memory.
This is the whole controversy raised by the paper and hence the paper has stirred the curiosity of the research community.
Visual Explanation
If you are a visual person like me and would like to watch a video of this article, here it is:
Conclusion and my takeaways
After reading the paper, without drowning in the controversy, my key takeaway is:
- Use reasoning mode only when the query is complex enough for the model.
- Providing too complex a query is not used either as the models can collapse without responding. Rather, break the problem and query the model in increments
- If the problem is too complex, don’t waste time with an LLM or LRM. Instead, realize AI is still a growing field and we are not there in AGI yet!
Hope that was useful! See you in my next...