Let's Build an AI Agent from Scratch in Raw Python

In this article, I am going to walk you through how I managed to implement a simple ReAct agent in “raw” Python without using any frameworks like LangChain, AutoGen, or CrewAI. Implementing a simple ReAct agent helped me understand clearly what's going on under the hood. It only boosted my confidence to build more complex agentic systems.
What is a ReAct Agent?
The Reason and Action (ReAct) framework was introduced in this paper titled, “ReAct: Synergizing Reasoning and Acting in Language Models”.
Language Models(LMs) are very good at generating reasoning traces. They are also good at taking some actions and getting observations from the environment based on their actions. For example, think of a chatbot interacting with a user. It responds to the user and gathers answers to keep going in a loop as a conversation. But the problem here is, that it doesn’t take any other action.
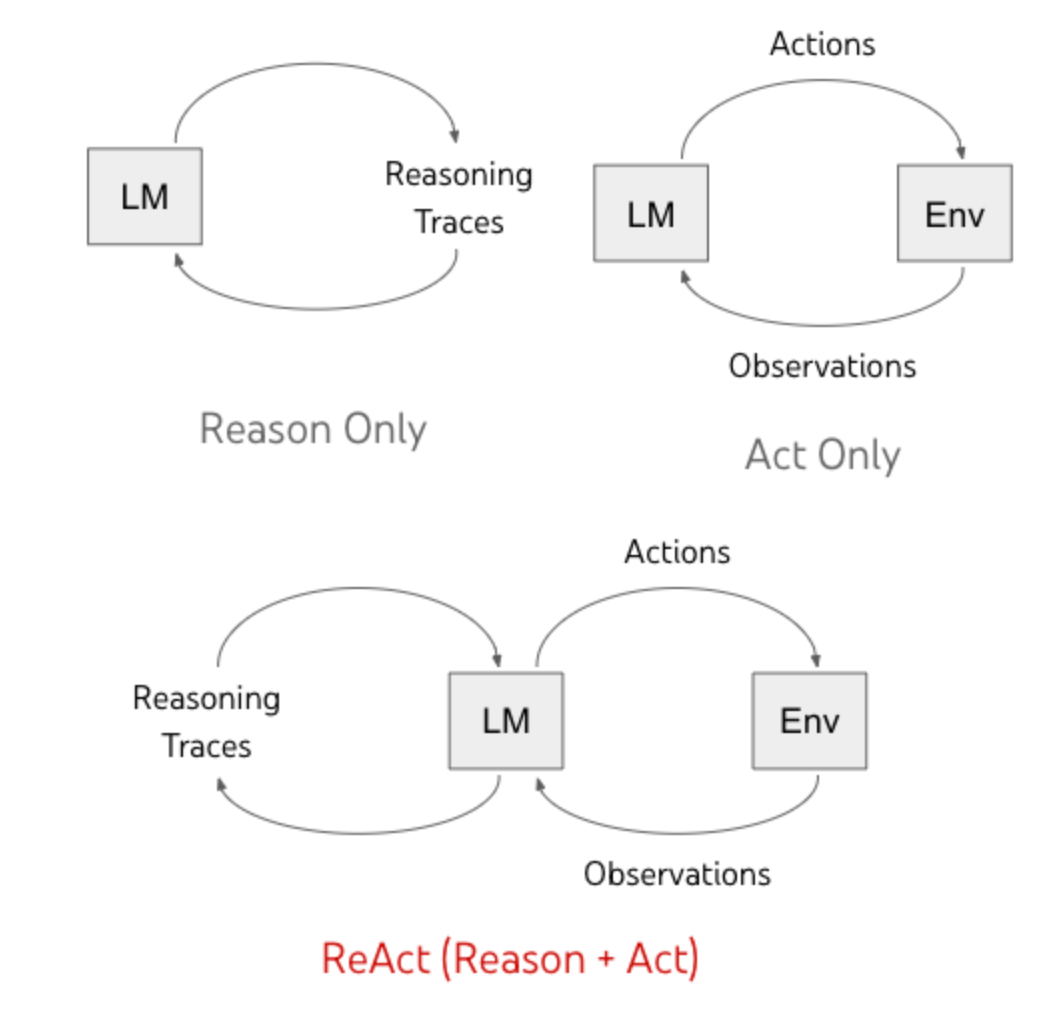
So, the action in the chat loop always remains the same. What if the two loops (reasoning and action) are put together? The action can then be diversified based on the reasoning. For example, the LM can decide to take another action such as referring to a Wikipedia page before responding to the user. This is a huge advantage and a leap in intelligence.
This is exactly what the ReAct paper proposed. People using this simple strategy started seeing a leap in the performance of LLMs. And so, the agentic era was born.
Problem Statement?
I want my LLM to not just respond in a loop, but browse Wikipedia or ArXiv (free research papers dump) or do simple calculations based on the user’s query.
We are going to solve this problem using a simple ReAct agent. We have an agent with an LLM at its heart. My choice of the LLM is OpenAI’s GPT-4o model. But we can have any LLM here. We then have 3 choices for the action:
- Action 1. ArXiv — The agent can query the ArXiv API to get data about any research publications relevant to the task
- Action 2. Wikipedia — The agent can query Wikipedia to gain any worldly knowledge about a given query
- Action 3. Calculator — The agent has a simple calculator at its disposal. It can be used to crunch numbers and output a result

The LLM can reason on its own, decide between any of the 3 actions, and go through them any number of times before responding to the user. Implementing this loop leads to our ReAct agent.
Implementation
Let's start by setting up the environment.
conda create -n “react-agent” python==3.12
conda activate react-agent
Let's then import the necessary packages. As we have chosen to implement in raw Python, we will only use OpenAI’s sdk for the LLM. Then httpx and requests to deal with API calls. So,
from openai import OpenAI
import re
import httpx
import requests
import xml.etree.ElementTree as ET
import json
Let us then set our OPENAI_API_KEY in a .env file and load it as below
from dotenv import load_dotenv
load_dotenv() # OPENAI_API_KEY
Let us do a quick check to see if the LLM works:
chat_completion = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "Hello there!"}]
)
chat_completion.choices[0].message.content'Hello! How can I assist you today?'
That seems alright.
ChatBot
Let's now create a chatbot that takes raw messages, stacks them together, and uses the LLM to respond to the messages.
class ChatBot:
def __init__(self, system=""):
self.system = system
self.messages = []
if self.system:
self.messages.append({"role": "system", "content": system})
def __call__(self, message):
self.messages.append({"role": "user", "content": message})
result = self.run_llm()
self.messages.append({"role": "assistant", "content": result})
return result
def run_llm(self):
completion = client.chat.completions.create(
model="gpt-4o",
temperature=0,
messages=self.messages)
return completion.choices[0].message.content
Nothing fancy here. If you were to build a simple chatbot without any agent, you would write the above code.
Agent
Let's wrap the above chatbot in our Agent class to create our beast — ReAct Agent.
class Agent:
def __init__(self, system_prompt="", max_turns=1, known_actions=None):
self.max_turns = max_turns
self.bot = ChatBot(system_prompt)
self.known_actions = known_actions
def run(self, question):
i = 0
next_prompt = question
while i < self.max_turns:
i += 1
result = self.bot(next_prompt)
print(result)
actions = [action_re.match(a) for a in result.split('\n') if action_re.match(a)]
if actions:
# There is an action to run
action, action_input = actions[0].groups()
if action not in self.known_actions:
raise Exception("Unknown action: {}: {}".format(action, action_input))
print(" -- running {} {}".format(action, action_input))
observation = self.known_actions[action](action_input)
print("Observation:", observation)
next_prompt = "Observation: {}".format(observation)
else:
return
The idea here is that we will create an agent by setting the max turns that the loop will go on as we don’t want the agent to go in an infinite loop. The agent also takes the chatbot and a known set of actions. We listed our 3 actions at the beginning of the article.
Actions
Let's now define actions as functions. The arxiv_search function will invoke arxiv API to fetch data for the agent. The Wikipedia function will use httpx to query Wikipedia and fetch knowledge about any topic unknown to the agent. The calculate function is a Python hack to evaluate any equations given to it.
def wikipedia(q):
return httpx.get("https://en.wikipedia.org/w/api.php", params={
"action": "query",
"list": "search",
"srsearch": q,
"format": "json"
}).json()["query"]["search"][0]["snippet"]
def arxiv_search(q):
url = f'http://export.arxiv.org/api/query?search_query=all:{q}&start=0&max_results=1'
res = requests.get(url)
et_root = ET.fromstring(res.content)
for entry in et_root.findall(f"{ARXIV_NAMESPACE}entry"):
title = entry.find(f"{ARXIV_NAMESPACE}title").text.strip()
summary = entry.find(f"{ARXIV_NAMESPACE}summary").text.strip()
return json.dumps({"title" : title, "summary" : summary})
def calculate(what):
return eval(what)
Prompt
Prompting is quite crucial for ReAct agents. They generally work by few-shot prompting. Meaning, we need to provide a few examples of what is expected of the agent in the prompt itself. For this reason, we need to write a detailed prompt with a few examples. Below is the prompt for the task.
prompt = """
You run in a loop of Thought, Action, PAUSE, Observation.
At the end of the loop you output an Answer
Use Thought to describe your thoughts about the question you have been asked.
Use Action to run one of the actions available to you - then return PAUSE.
Observation will be the result of running those actions.
Your available actions are:
calculate:
e.g. calculate: 4 * 7 / 3
Runs a calculation and returns the number - uses Python so be sure to use floating point syntax if necessary
wikipedia:
e.g. wikipedia:
Returns a summary from searching Wikipedia
arxiv_search:
e.g. arxiv_search:
Returns a summary of research papers
Example session:
Question: What is the capital of France?
Thought: I should look up France on Wikipedia
Action: wikipedia: France
PAUSE
You will be called again with this:
Observation: France is a country. The capital is Paris.
You then output:
Answer: The capital of France is Paris
""".strip()
Nothing fancy here other than pro-level prompting. We have listed all the actions, explicitly mentioned, “run in a loop of Thought, Action, PAUSE, Observation” so that the agent can invoke actions and think of the perceived observations.
Test the Agent
It's time to test out our ReAct agent. Let's collate all the actions in a dictionary, create an instance of the agent, and invoke its run method to run the agent.
known_actions = {
"wikipedia": wikipedia,
"calculate": calculate,
"arxiv_search": arxiv_search
}
agent = Agent(prompt, max_turns=3, known_actions=known_actions)
agent.run("what is the capital of indonesia?")
Below is the reasoning trace and the response:
Thought: I should look up Indonesia on Wikipedia to find out its capital.
Action: wikipedia: Indonesia
PAUSE
-- running wikipedia Indonesia
Observation: <span class="searchmatch">Indonesia</span>, officially the Republic of <span class="searchmatch">Indonesia</span>, is a country in Southeast Asia and Oceania, between the Indian and Pacific oceans. Comprising over 17
Answer: The capital of Indonesia is Jakarta.
Let's try out another query.
agent.run("explain the lightrag paper")Thought: I should search for the "lightrag paper" to find relevant information about it, as it seems to be a specific research topic or publication.
Action: arxiv_search: lightrag
PAUSE
-- running arxiv_search lightrag
Observation: {"title": "LightRAG: Simple and Fast Retrieval-Augmented Generation", "summary": "Retrieval-Augmented Generation (RAG) systems enhance large language models\n(LLMs) by integrating external knowledge sources, enabling more accurate and\ncontextually relevant responses tailored to user needs. However, existing RAG\nsystems have significant limitations, including reliance on flat data\nrepresentations and inadequate contextual awareness, which can lead to\nfragmented answers that fail to capture complex inter-dependencies. To address\nthese challenges, we propose LightRAG, which incorporates graph structures into\ntext indexing and retrieval processes. This innovative framework employs a\ndual-level retrieval system that enhances comprehensive information retrieval\nfrom both low-level and high-level knowledge discovery. Additionally, the\nintegration of graph structures with vector representations facilitates\nefficient retrieval of related entities and their relationships, significantly\nimproving response times while maintaining contextual relevance. This\ncapability is further enhanced by an incremental update algorithm that ensures\nthe timely integration of new data, allowing the system to remain effective and\nresponsive in rapidly changing data environments. Extensive experimental\nvalidation demonstrates considerable improvements in retrieval accuracy and\nefficiency compared to existing approaches. We have made our LightRAG\nopen-source and available at the link: https://github.com/HKUDS/LightRAG"}
Answer: The LightRAG paper, titled "LightRAG: Simple and Fast Retrieval-Augmented Generation," presents a system that enhances large language models by integrating external knowledge sources. This approach aims to provide more accurate and contextually relevant responses. LightRAG addresses limitations in existing Retrieval-Augmented Generation (RAG) systems, such as reliance on flat data representations and inadequate contextual awareness, which can lead to fragmented answers. It incorporates graph structures into text indexing and retrieval processes, employing a dual-level retrieval system for comprehensive information retrieval. This system improves response times and maintains contextual relevance by efficiently retrieving related entities and their relationships. LightRAG also features an incremental update algorithm for timely integration of new data, ensuring effectiveness in rapidly changing environments. The paper reports significant improvements in retrieval accuracy and efficiency, and the LightRAG system is available as open-source at the provided GitHub link.
Notice the action above. We never asked it to use arxiv search. We only asked about the LightRAG paper. It is understood that LightRAG is a research work and decided to choose the arxiv search action.
Isn’t that amazing?? :-)
Here is the Code
The code for what we have seen is all available for free here. Hope it helps!
Visual Explanation
If you are more visual like me and would like a visual explanation, here it is:
Hope to see you in my next!