Gone are those days of AI

This week I am taking a slight detour from my usual articles that explain AI Concepts or coding tutorials. Yes, it's a philosophical, nostalgic tour down the road I was fortunate enough to tread all along.
One of the rare privileges of starting in a field quite early is that you see the field grow like your baby. When I started my Masters in Computer Vision a decade ago, a CS graduate friend of mine asked, “What does computer vision even mean?”. It's a trivial question today with enough videos of computer vision tasks like segmentation (see below) floating around the internet.

So, what has changed in the last decade? There is always two sides to a coin. Also, growth can be both good and bad.
Closed Community — Small was beautiful
They say that people in Iceland are somehow related to each other and if someone is beyond your second cousin, you are good to marry them.
Likewise, the AI community was close knit. Gone are those feelings of a tight-knit community. When interacting with anyone from research you generally knew which group they belonged to. You somehow would relate to and respect their work as you read and appreciated their impact on the field. As the field is blowing up endlessly, it's becoming increasingly difficult to even say that you know someone’s work, forget about them. There are too many new names and novel branches that it's even challenging to keep track of.
As another example, PyTorch was in its infancy. The Slack community was so small and helpful that the developers of PyTorch directly responded to questions we had about using the library. This encouraged learning more and more about it. Today the framework is so mature and new frameworks like LangChain and Llamaindex have propped up. The focus is all on LLMs over any other brach of AI.
Hardware luxury
Those days we used to train a deep neural network on a single GPU to create something impactful. Most work published in premier conferences like CVPR, NeurIPS, and ICML could be trained and replicated on a single 8 GB GPU machine or in the worst case, a single machine with 4 GPUs in rare cases.

I vividly remember how happy I was to buy a single commodity GPU with just 8 GB of RAM to participate in Kaggle competitions. Some of the winning solutions from Kaggle Grandmasters trained deep learning models on a single GPU machine at home.
Today’s AI world needs a GPU cluster to train foundational models. Even fine-tuning of these models needs 24GB GPUs which are beasts, expensive and affordable only by businesses with “AI budget”.
Skillset demand
Those were days when the field did not yet get the AI wrapper around it. Recruiters were given this alien task of hunting for “deep learning” engineers. Recruiters and start-up founders were hunting for deep learning experts through all channels. It was a norm to receive regular messages on LinkedIn asking me to join their team as a deep learning engineer.
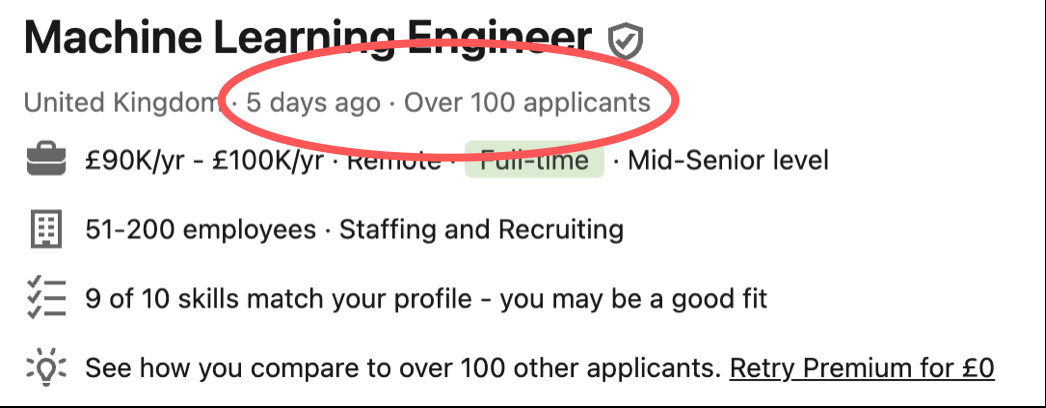
The current situation is that openings for “Machine Learning Engineer” get over 100 applications on LinkedIn well within a day of advertising. Take a look at the screenshot above if you find it hard to believe. Question remains as to how relevant the applicant's skills are to the job spec. But the market is staurating with skills — quite quickly!
Sub-skills — Operations and Architecture
Growth means more diversity and opportunity. There are new roles like ML-ops, LLM-ops, and ML-architects cropping up. Gone are those days of tiny, single-model files (< 1 GB). The growth of models both in size and capabilities has given rise to new skills in deploying and maintaining them. Moreover, training and deployment of models is being automated with tools such as MLFLow. The cloud infrastructure for training needs to be sophisticated enough. All this has given rise to full-time roles with dedicated responsibilities.
Bye bye ML Engineer, hello AI Engineer
The most fun in working in AI is writing the model architecture, and training the model from scratch using our in-house data. Though this involves pre-processing the data a lot, training models, and visualizing the training results used to be a lot of fun. There was/still is a specialized role for this called Machine Learning(ML) Engineer.
The development of foundation models from tech giants is redefining this role. As model sizes grow, training budgets are enormous. As a matter of fact, the cost of training the LLama 2 model was $20m for Meta. Clearly start-ups or organizations trying to adopt AI do not wish to throw away this sum of money. It is now established that foundation models are for the tech giants to develop, with the exception of some companies like Mistral and Anthropic.
Sadly this means, the ML Engineer role is getting cast into an AI Engineer role. The ML Engineer role was all about developing model architectures, training and evaluating them. The new AI Engineer role mostly involves developing APIs or invoking APIs provided by Tech giants (OpenAI, Meta and Google) to prompt the foundation models. In rare cases it involves fine-tuning these foundation models. But companies are option to build RAG pipelines or using the foundation models “as-is” over fine-tuning them.
Conclusion
To conclude, I see this as a slow amalgamation of the Software engineering and Machine Learning roles. The line between software engineers and deep learning experts is fading. So in the years to come software engineers will be AI engineers who work alongside foundation models, both to write code and to solve customer needs.
Furthermore, in the coming years, companies will be grouped into two categories — the AI product and AI services companies. AI product companies would again be OpenAI, Meta, and Google to develop foundational models. AI services companies would provide API services by fine-tuning or developing RAG-style pipelines around AI foundational models to serve their customers.
Lastly, does the spike in job applications indicate an impending bursting of the bubble like to dot com bubble? I feel so, YES. But lets wait and watch it…